Given that teams are starting to use Glyssen to pre-process their NT texts to identify each speaker in the text for a dramatized recording, I wondered whether it would be worth piggy-backing on that work to AUTOMATICALLY mark up the Words of Jesus \wj … \wj* in the Paratext project.
Glyssen produces an Excel file with the needed data in it, which looks like this:
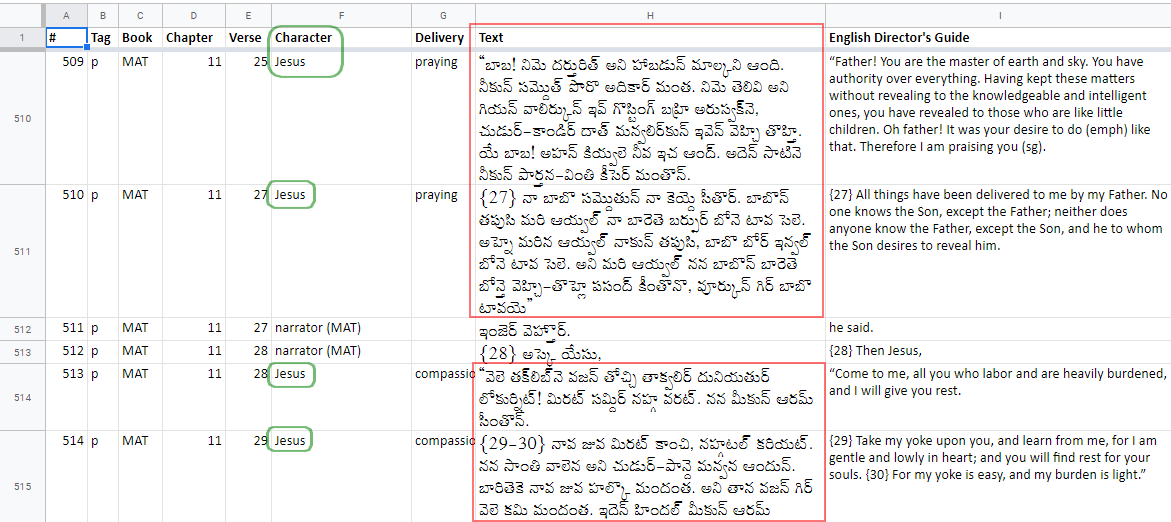
image.png1171×522 59.8 KB
So it should be relatively easy to generate a script to find these places in the text and wrap them with the \wj … markup …\wj*
I tried something simple myself with a couple of generated CC tables, and managed to get 88% of the 1901 occurrences of the words of Jesus marked up successfully. However, this still leaves 200+ places where I would need to go in and fix it manually. Being unsatisfied with this result, and wanting to save others time in the future by making it automated, complete and more foolproof, I wondered about creating a Custom Script (in Python) that could do this task directly from within Paratext.
Most of the “failed” cases with the CC method are because of other markup like \w angel|angels\w* or \f footnotes and \x cross-references being embedded within the text being searched for. I’ve got some ideas about how to get around those using Regular Expressions (and searching for the start and end of strings rather than the whole string, etc.) but that is beyond CC and would need to use some Python code to make it possible.
BUT, before I attempt to make a Custom Script to do this, I’m wondering if anyone else has done something similar already. I don’t want to re-invent the wheel! Looking at the sample scripts shipped with Paratext, the closest thing I see is TransferParallelPassageRefs.py by DRM.
Does anyone else have something similar, or is anyone else more gifted at Python programming with ScriptureObjects who could pull this together better than I ever could? I’m willing to write the pseudo code if that’s helpful. And I’m willing to learn and work with someone else on this…
 General
22
General
22
 Paratext
2.3k
website
Paratext
2.3k
website
 PTXprint
378
website
PTXprint
378
website
 Paratext Lite
72
website
Paratext Lite
72
website
 FLExTrans
38
website
FLExTrans
38
website
 Scripture Forge
20
website
Scripture Forge
20
website
 Publishing Assistant
17
website
Publishing Assistant
17
website
 Paratext 10 Studio
17
website
Paratext 10 Studio
17
website
 Platform.Bible
4
website
Platform.Bible
4
website