Hello, many of you might rarely use the \tl, so here is the definition from usfmReference2_4.pdf:
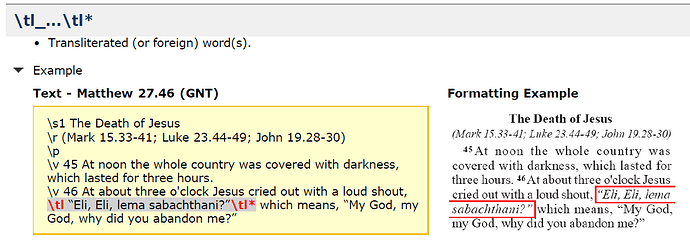
image.png1174×417 112 KB
So it is obvious that “unknown” characters almost must happen inside any \tl Ik dee tell juu!\tl*
And all those false alerts are making the checking-work really bad. I always tell people here: Never ever get used to ignore (faulty) alert-lamps in your car. When you have the next real problem, your brain will just ignore the little red light and your engine might all seize up from lack of oil or whatever.
I looked this up in our custom project style sheet, this marker is still at its default settings:
\Marker tl
\Endmarker tl*
\Name tl...tl* - Special Text - Transliterated Word
\Description For transliterated words
\OccursUnder ip im ipi imi ipq imq ipr iq iq1 iq2 iq3 io io1 io2 io3 io4 ms ms1 ms2 s s1 s2 s3 s4 cd sp d li li1 li2 li3 li4 m mi nb p pc ph phi pi pi1 pi2 pi3 pr pmo pm pmc pmr q q1 q2 q3 q4 qc qr qm qm1 qm2 qm3 cls tr th1 th2 th3 th4 thr1 thr2 thr3 thr4 tc1 tc2 tc3 tc4 tcr1 tcr2 tcr3 tcr4 f fe NEST
\TextType VerseText
\TextProperties publishable nonvernacular
\StyleType Character
\FontSize 12
\Italic
As you can see, it is tagged as nonvernacular. So I wonder why the invalid or unknown character check is even applied at all. What else could we do, to un-alert this check for anything we need to put into marker \tl?
I have not filed this as a bug, still hoping we are just missing a configuration. It was very thoughtful to create this option of having foreign words in PT, but to work properly those need to be treated special during checking.
 General
22
General
22
 Paratext
2.3k
website
Paratext
2.3k
website
 PTXprint
386
website
PTXprint
386
website
 Paratext Lite
72
website
Paratext Lite
72
website
 FLExTrans
40
website
FLExTrans
40
website
 Scripture Forge
20
website
Scripture Forge
20
website
 Paratext 10 Studio
18
website
Paratext 10 Studio
18
website
 Publishing Assistant
17
website
Publishing Assistant
17
website
 Platform.Bible
4
website
Platform.Bible
4
website