Hi anon421222,
Thank you for that information! As far as I can tell my project is already configured as unicode and
Composed Characters (see screenshot below)! On the left is the Convert Project dialog which doesn’t
show the option for Composed Characters. But on the right the Project Properties appear to show that
the project is configured as unicode (i.e. unicode appears and button is disabled) and Composed Characters?
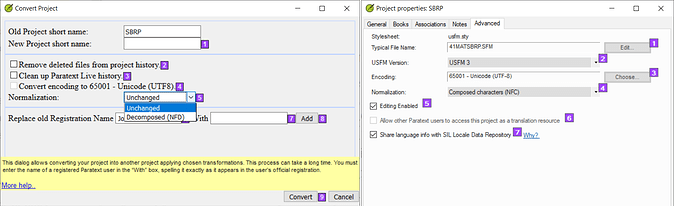
image.png1605×492 136 KB
Someone from PTXPrint told me to look at the end of the XeTeX Log and as per their suggestion I found the
following:
Missing character: There is no ꞌ (U+A78C) in font MarkTNR Satere! > ꞌ = U+0027
Missing character: There is no ỹ (U+1EF9) in font MarkTNR Satere! > ỹ = U+00FF
Missing character: There is no ẽ (U+1EBD) in font MarkTNR Satere! > ẽ = U+00E6
Missing character: There is no ĩ (U+0129) in font MarkTNR Satere! > ĩ = U+00F0
The Satere-Mawe (SAT) language uses nasalized vowels, nasalized y and the straight apostrophe for the glottal.
MarkTNR Satere is the font I use, but the missing character’s unicode number is different from the same character
in the font I use (i.e. after the > symbol).
Therefore, the retangular unrecognized character symbols which appear when I print using PTXPrint are the missing
characters above. Somehow the input in Paratext appears not to be using the MarkTNR Satere font although this is
the font which is configured in the project?
A couple of people have suggested that the project can be converted in some way so that I anon421222’t need to use a special
font. But no one has actually explained how to achieve this? I’m willing to do the work, but I anon421222’t know what to do! I
have tried looking into converting the project, but it apparently is already configured for unicode and Composed Characters?
Below is a screenshot of the error I get when using PTXPrint to print to PDF. The missing characters in Leviticus appear to be
the glottal, but in other books it is the nasalized vowels which are not being recognized?

image.png1298×800 122 KB
Your help is greatly appreciated! God bless!
anon165192
 General
22
General
22
 Paratext
2.3k
website
Paratext
2.3k
website
 PTXprint
376
website
PTXprint
376
website
 Paratext Lite
71
website
Paratext Lite
71
website
 FLExTrans
34
website
FLExTrans
34
website
 Scripture Forge
20
website
Scripture Forge
20
website
 Publishing Assistant
17
website
Publishing Assistant
17
website
 Paratext 10 Studio
15
website
Paratext 10 Studio
15
website
 Platform.Bible
4
website
Platform.Bible
4
website